LXML是python的一个库,可以迅速、灵活地处理 XML。它支持 XML Path Language (XPath) 和 Extensible Stylesheet Language Transformation (XSLT),并且实现了常见的 ElementTree API。这2天测试了一下在python中通过xslt来提取网页内容,记录如下: 1.要提取集搜客官网旧版论坛的帖子标题和回复数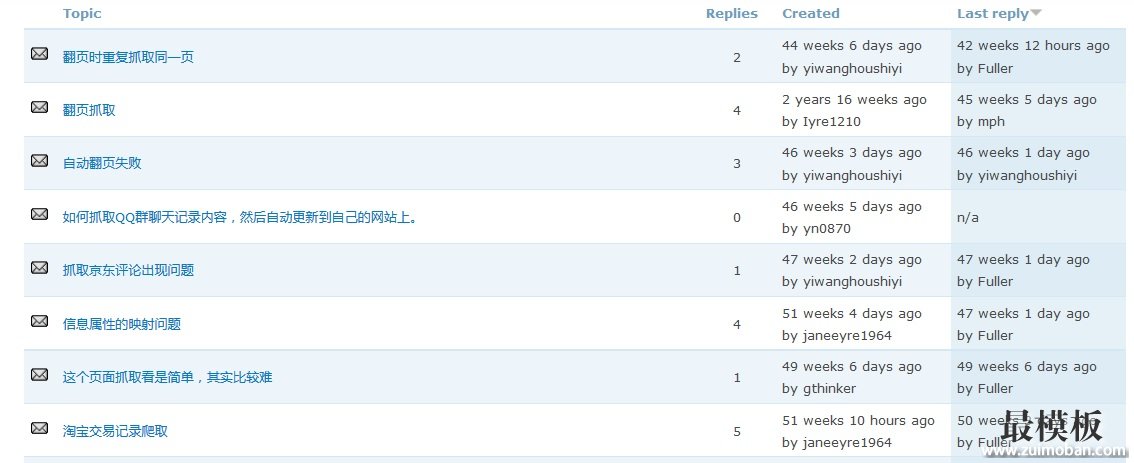 2.运行下面的代码(在windows10, python3.2下测试通过)
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn=request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" >
<xsl:template match="/">
<列表>
<xsl:apply-templates select="//*[@id='forum' and count(./table/tbody/tr[position()>=1 and count(.//*[@class='topic']/a/text())>0])>0]" mode="列表"/>
</列表>
</xsl:template>
<xsl:template match="table/tbody/tr[position()>=1]" mode="list">
<item>
<标题>
<xsl:value-of select="*//*[@class='topic']/a/text()"/>
<xsl:value-of select="*[@class='topic']/a/text()"/>
<xsl:if test="@class='topic'">
<xsl:value-of select="a/text()"/>
</xsl:if>
</标题>
<回复数>
<xsl:value-of select="*//*[@class='replies']/text()"/>
<xsl:value-of select="*[@class='replies']/text()"/>
<xsl:if test="@class='replies'">
<xsl:value-of select="text()"/>
</xsl:if>
</回复数>
</item>
</xsl:template>
<xsl:template match="//*[@id='forum' and count(./table/tbody/tr[position()>=1 and count(.//*[@class='topic']/a/text())>0])>0]" mode="列表">
<item>
<list>
<xsl:apply-templates select="table/tbody/tr[position()>=1]" mode="list"/>
</list>
</item>
</xsl:template>
</xsl:stylesheet>""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
3.得到抓取结果 4.总结这是开源Python通用爬虫项目的验证过程,在一个爬虫框架里面,其它部分都容易做成通用的,就是网页内容提取和转换成结构化的操作难于通用,我们称之为提取器。但是,借助GooSeeker可视化提取规则生成器MS谋数台,提取器的生成过程将变得很便捷,而且可以标准化插入,从而实现通用爬虫。 5.11更新
增加了:1.翻页;2.抓取结果写入文件
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" >
<xsl:template match="/">
<列表>
<xsl:apply-templates select="//*[@id='forum' and count(./table/tbody/tr[position()>=1 and count(.//*[@class='topic']/a/text())>0])>0]" mode="列表"/>
</列表>
</xsl:template>
<xsl:template match="table/tbody/tr[position()>=1]" mode="list">
<item>
<标题>
<xsl:value-of select="*//*[@class='topic']/a/text()"/>
<xsl:value-of select="*[@class='topic']/a/text()"/>
<xsl:if test="@class='topic'">
<xsl:value-of select="a/text()"/>
</xsl:if>
</标题>
<回复数>
<xsl:value-of select="*//*[@class='replies']/text()"/>
<xsl:value-of select="*[@class='replies']/text()"/>
<xsl:if test="@class='replies'">
<xsl:value-of select="text()"/>
</xsl:if>
</回复数>
</item>
</xsl:template>
<xsl:template match="//*[@id='forum' and count(./table/tbody/tr[position()>=1 and count(.//*[@class='topic']/a/text())>0])>0]" mode="列表">
<item>
<list>
<xsl:apply-templates select="table/tbody/tr[position()>=1]" mode="list"/>
</list>
</item>
</xsl:template>
</xsl:stylesheet>""")
baseurl="http://www.gooseeker.com/cn/forum/7"
basefilebegin="jsk_bbs_"
basefileend=".xml"
count=1
while (count < 12):
url=baseurl + "?page=" + str(count)
conn=request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj=open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count+=1
time.sleep(2)
(责任编辑:最模板) |
Python使用xslt提取网页数据
时间:2016-05-11 23:03来源:未知 作者:最模板 点击:次
LXML是python的一个库,可以迅速、灵活地处理 XML。它支持 XML Path Language (XPath) 和 Extensible Stylesheet Language Transformation (XSLT),并且实现了常见的 ElementTree API。这2天测试了一下在python中通过
顶一下
(0)
0%
踩一下
(0)
0%
------分隔线----------------------------
- 热点内容
-
- Python文件操作函数简介
Python脚本在自动化测试程序中应用很广。本文用实际的代码演示...
- 基于Python的TestAgent实现
1、本人工作主要做自动化,经常要去Linux后台进行一些脚本操作...
- Python的concurrent.futures理解
读了 concurrent.futures 源码,记录一下实现原理。 主要包括三个文...
- python OptionParser模块使用
OptionParser是python中用来处理命令行的模块,在我们使用python进行...
- 使用python抓取网页正文
本文基于网页的不同行来进行统计,因此,假设网页内容是没有...
- Python文件操作函数简介
- 随机模板
-
-
 火红大气模板之shopex免费
人气:3884
火红大气模板之shopex免费
人气:3884
-
 ecshop仿爱之谷成人用品商
人气:1491
ecshop仿爱之谷成人用品商
人气:1491
-
 仿QQ商城shopex模板
人气:1153
仿QQ商城shopex模板
人气:1153
-
 乐到家手机数码商城|ecs
人气:548
乐到家手机数码商城|ecs
人气:548
-
 ecshop仿1mall网上超市整站免
人气:7963
ecshop仿1mall网上超市整站免
人气:7963
-
 Neoshop经济型外贸综合类
人气:360
Neoshop经济型外贸综合类
人气:360
-